GCP上でのETLいろいろ
Courseraの「 Building Batch Data Pipelines on GCP」を受講した上での整理。
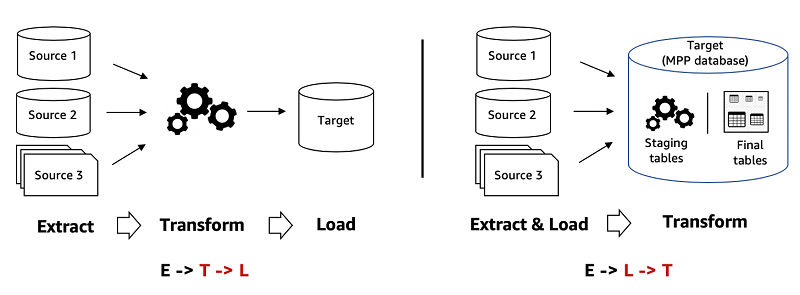
ETLとは?
Extract, Transform, Loadのこと。
データソース(多くは各アプリケーションから蓄積しているDBやストレージ) => 変換処理 => 一元的なデータ置き場(DB, DWHなど)という流れになる。
ELT, ELもある。これらとの違いは変換処理の有無や順番。
Transformが単純なSQLで書けない(もしくは書きづらい)ような複雑なものであったりTransformに時間がかかる場合はETL, そうでない場合はELT, TransformなしでいけるならELという感じ。
有名でよくサンプルとして使われる、ファイル内の単語数を単語ごとに集計する Word Countというタスクがある。
GCPにおけるETLの選択肢
欲しい機能・非機能要件によって色んな選択肢がある。
- Dataproc
- Data Fusion
- Dataprep
- Dataflow
AWSとの比較ドキュメントとして 「AWS プロフェッショナルのための Google Cloud: ビッグデータ」も公式に記載があるので興味がある場合見てみると良い。
Dataproc
GCP上でマネージドにHadoop, Sparkなどの分散コンピューティングを利用できる。
Hadoopとはなんぞや、な場合はこの辺を参照: 分散処理技術「Hadoop」とは | NTT Data
- オンプレミス上でHadoopを利用する場合、ストレージとコンピューティングリソースの分離がしづらく、HDFSに永続化しておくためにクラスタを常時起動しておかないといけない、という困り事がある。
- DataprocではGCSにデータを永続化しておくことが推奨されている。
- GCSでも超高速(1Pbit/s)な内部ネットワーク(Jupiterネットワーク)で接続されている( 2分割帯域)ため遅延は少ない。(とはいえローカルSSDよりは低速)
- これによりクラスタはいつでも起動・停止可能。
hdfs://をgs://に書き換えるだけ。
- コンピューティングリソースをいつでも拡張・縮小可能。
- Auto Scalingもある(頻発する際はAuto Scalingが得意なDataflowへの置き換えが推奨されている)
- アイドル状態のクラスタを自動削除することも可能。
ユースケース
- オンプレミスでHadoop, Sparkなどをすでに利用していてクラウド移行したい場合
- 基本的にリフト&シフトが可能(永続化にGCS利用する修正くらいはお手軽だし効果大なのでやったほうが良い)
GCSではなくHDFSをストレージとして利用した方が良いケース
- メタデータ(パーティションやディレクトリなど)の更新が頻繁に行われる
- ファイルサイズが小さい
- ディレクトリのリネーム操作が多い時(GCSはディレクトリのリネームが遅い。というか全コピーが走る)
- append操作が多い
- パーティション分割した書き込みなど重い操作が多い
- 数ミリsecのレイテンシも許容できない
ただしこれらの場合でも中間データはHDFSを利用するとして、最初と最後(つまり永続化)にはGCSを利用すべき。
また、HDFSにSSDではなくHDDを利用すると速度の恩恵はほとんどない。
よりクラウド最適化するために
オンプレミスのHadoop, Sparkコードをリフト&シフトで利用できるものの、元のコードの作りによってはクラウドの恩恵を最大化するために改善できることもある。
具体的には、処理がエフェメラルクラスタとなるよう工夫すべき。
つまり永続化にはGCSなどHDFS以外を利用し、コンピューティングとストレージとの分離を図る。
これによってクラスタリソースはいつでも破棄可能となり、クラスタリソースサイズの縮小、自動削除、プリエンプティブルVMの利用がしやすくなる。
例えば、Dataprocのクラスタ上でJupyter notebookなどを起動できるがいつもここから実行しているとクラスタを削除しづらい。(ついnotebookのローカルストレージに一時ファイルを保存しちゃうなど)
Hadoop/Sparkの実行はスタンドアロンなスクリプトとして括りだしておき、クラスタ外部からジョブとして実行できるようにしておくと良い。(クラスタを単にコンピューティングリソースとしてだけ利用する)
使い方概要
- Clusterを起動。
- 冗長構成, マシンスペック, Hadoop/Sparkのバージョンとか選べる
- 起動するとVMインスタンス, 作業用のGCSとかが勝手に作られる
- Jupyter notebookとかも起動できる。
gs://<自動的に作られるバケット>/notebooks/jupyter配下がmountされているのでこのGCSにアップロードすればDataproc内のJupyter notebookから参照可能。- このJupyter notebookにもDataprocのGCPコンソール上に表示されるリンクからシームレスに接続可能。
- Jupyterはマスターノードで起動している様子。
- ジョブを実行。
- Hadoop/SparkのSDKを使って実行 or
gcloud dataprocコマンドからジョブとして起動。 - 前者はコンソール上に実行記録は残らないが、後者は記録が残る。
- Clusterを停止。
- この時点でほぼ課金(VMインスタンスが停止する)はストップになるはず。
- HDFSに保存されたデータは残る。(メモリのみのデータは当然消える)
- Clusterを削除。
- クラスタに利用されていたVMインスタンスが削除される。
- 上記の作業用のGCSも削除される…と思いきや残るっぽい。けど、念の為永続化用のGCSは自前で別に用意した方がよさそう。
Data Fusion

- GUIでETLが組める。内部ではDataprocが走る。
- Dataprocのクラスタは自動起動・削除される。
- 既存のDataprocクラスタにプロビジョニングすることも可能。
- 将来的にはDataflowでの実行もサポートされる予定。
- パイプラインのテンプレート化も可能。
- 「データリネージ」の追跡が可能。
- データの派生元, 変換した内容, メタデータなど。
- Data Fusion Studioを使ってGUI上でDAGを定義してパイプラインを構築していく。
- 各ノードはあらかじめ処理が定義されていてコーディングは不要。
- スケジューリング実行機能もあり。
- バッチ処理のみ。ストリーミング処理はDataflowにて。
想定されるユースケースとしては「GUIでETLを組みたい」の一点に尽きると思う。
手軽に試せるしexportもできるので資産管理もある程度可能、スケールもある程度やってくれる。ローコードでETLを実践したいときに便利。
Dataflow
GCPでのETL本命。
フルマネージドなApache BEAM(Batch + strEAM)
Dataflowの特長
- サーバレスな分散データパイプラインを構築。
- ジョブ実行中に動的なオートスケーリング
- 単にワークフローを構築するだけでなく、内部でグラフの最適化が行われる。
- Apache Beam環境さえ構築できればどこでも動く
- 例えばPythonであればpip installで構築可能
- SDKの初期化時にDataflowRunnerを指定する(SDK側でGCPがサポートされている)
- Dataflow TemplatesというGoogleが用意しているテンプレートから始めることもできる。
- 独自のテンプレートも作成可能。
- 単にサンプルがあるというだけではなく、開発者と実行者を分離できるというメリット(コンパイルの再実行を防いだり)
- バッチとストリームをどちらも同じプログラミングモデルで処理可能なのが最大の特長
- バッチではGCSなど有限な入力
- ストリームではPubSubなど無限の入力をウィンドウに区切って処理していく
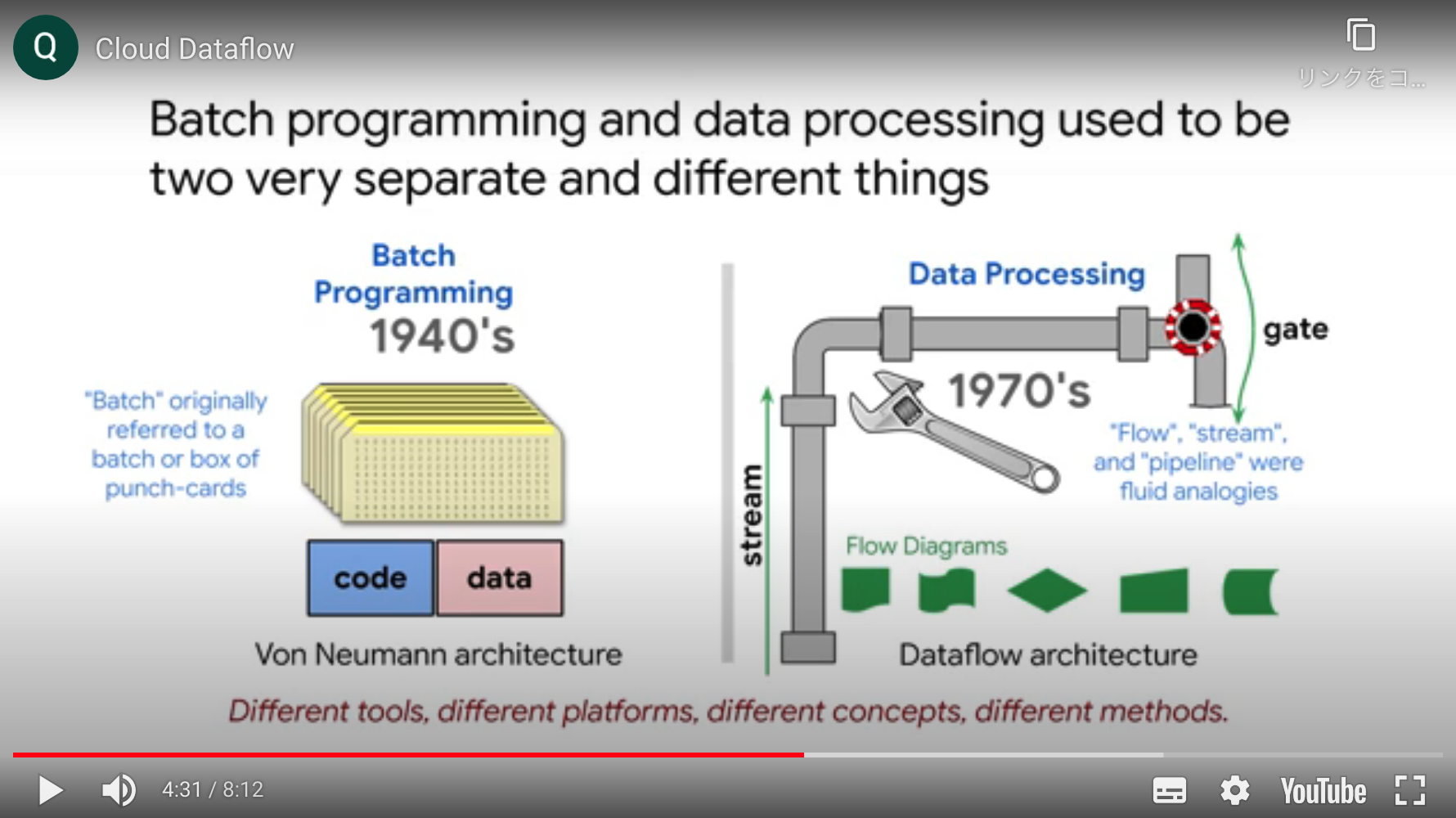
バッチとストリーミング
- バッチは開始と終了がある有限のデータを処理する
- 1940年代、パンチカードで処理していた。このパンチカードの塊をバッチと呼んでいた。
- ストリーミングは流動的な水の流れのような持続的なもの
- 処理自体は細切れにされたマイクロバッチで処理されることが多い
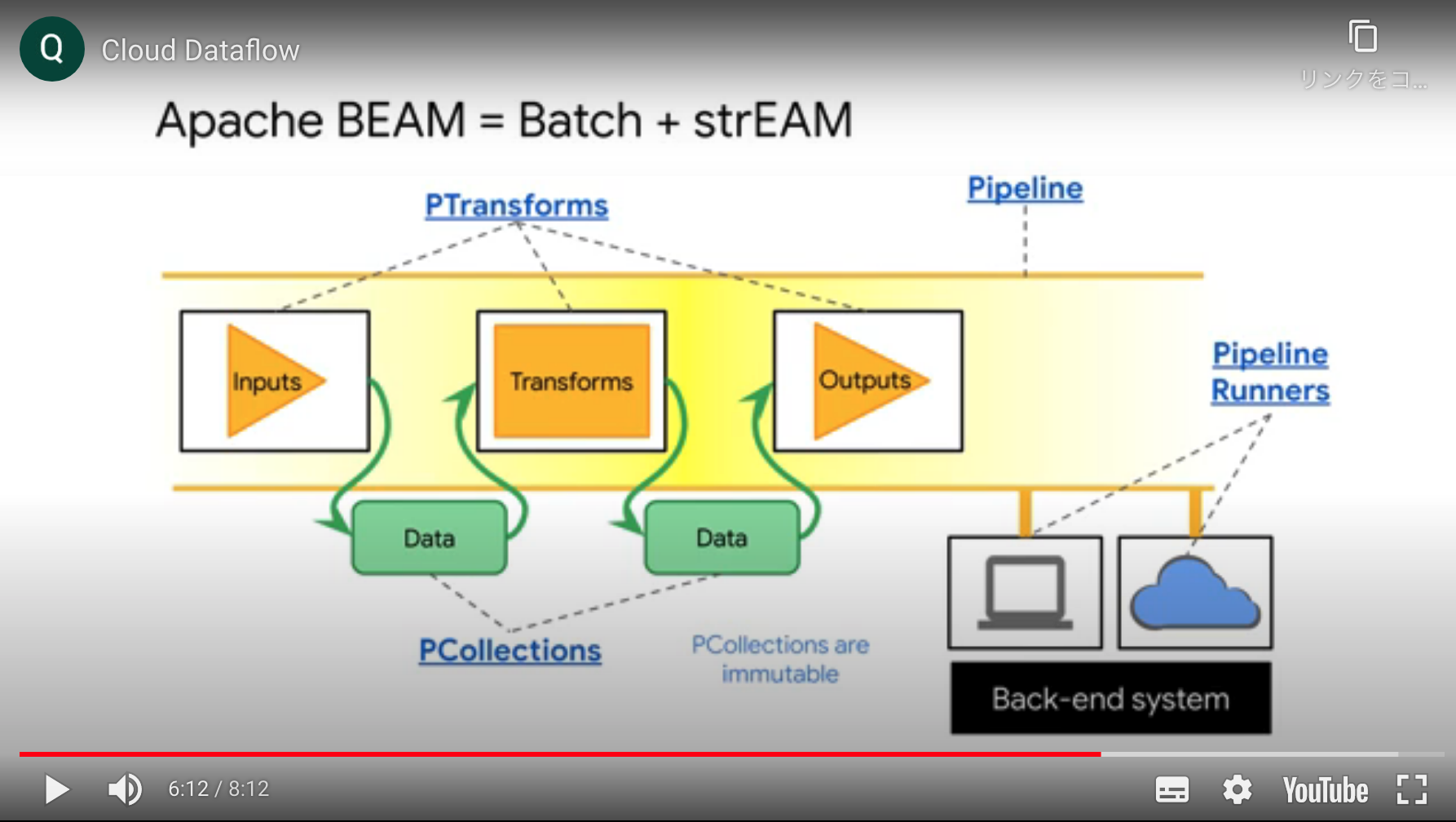
Dataflowでどちらも同じように処理可能としているのは以下の4つの概念。
- PTransforms: 処理
- PCollections: データ
- データはすべてバイト列にシリアライズされて保持。これによりネットワーク転送時にデシリアライズする必要なし。
- Pipeline: ワークフロー
- Pipeline Runnners: 処理クラスタ
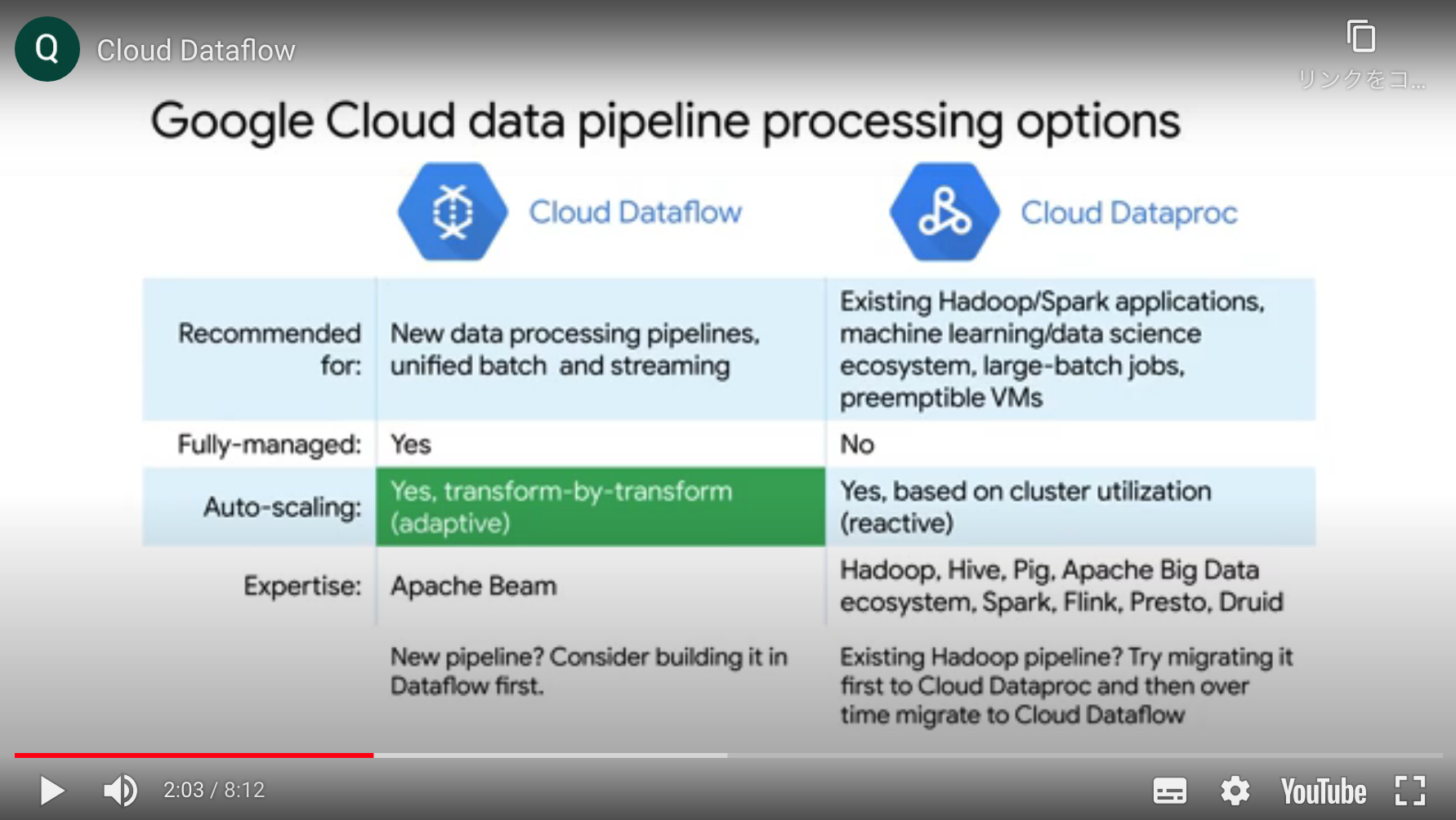
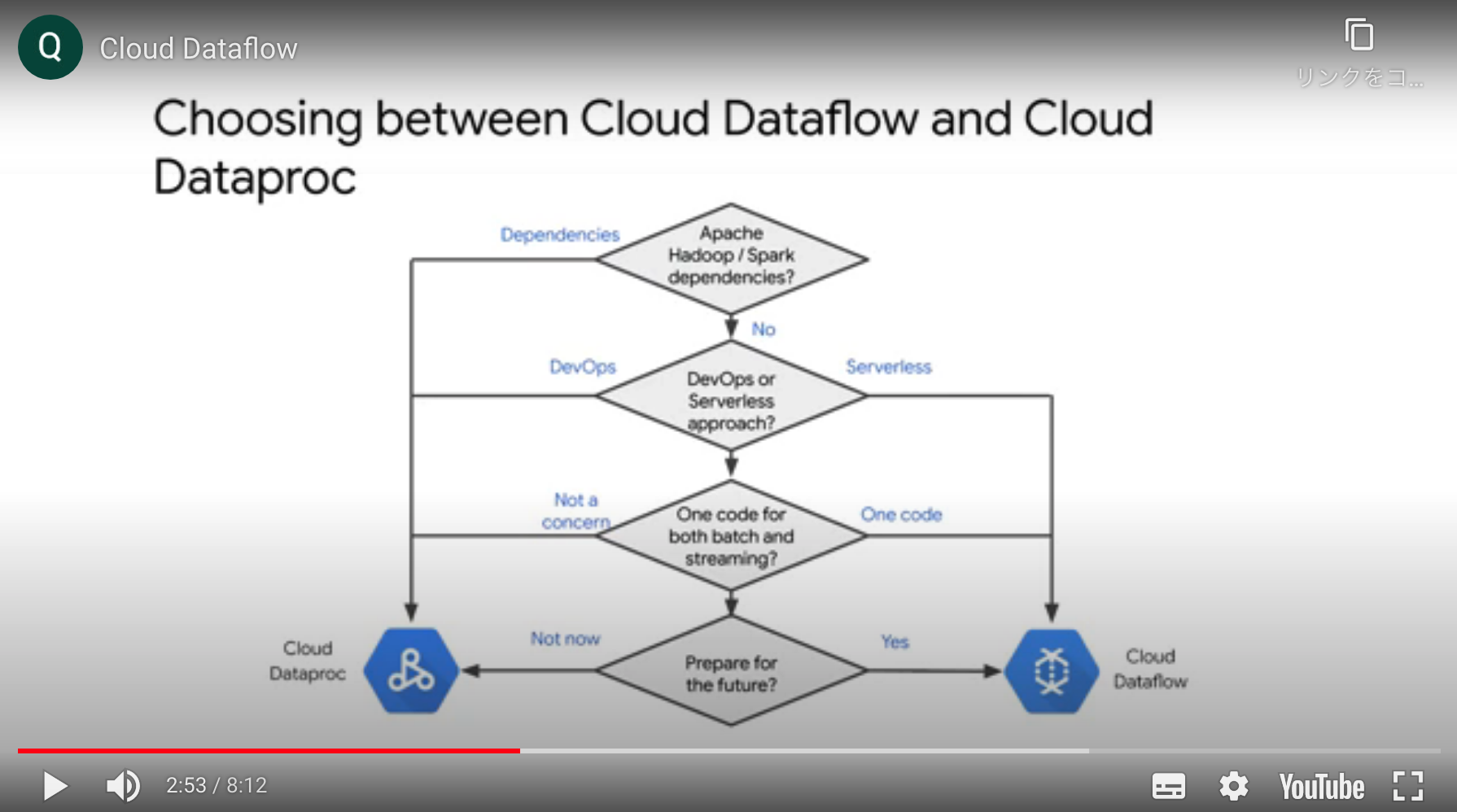
Dataprocとの使い分け
基本的にGoogleはDataflow推しの様子。
- 既存のHadoop, Spark資産を使いまわしたかったらDataproc, それ以外はDataflow
- サーバレスではなくクラスタ管理を自分たちで行いたい場合(DevOpsアプローチに慣れている場合)Dataproc, それ以外はDataflow
補足
- GroupByKeyは非効率なのでCombineの使用を検討する。
- MapReduceとのプログラミングモデルの違い
- MapはPCollection, PTransformに相当
- ReduceはCombine
ストリーミングデータについて
難しさ
- データの量が変動するため、マシンリソースの柔軟なスケーリングが求められる
- 遅延データがある。正確性と応答速度がトレードオフ
- 正確性を重視し遅延データを待ちすぎると、速度が下がる
- リアルタイム性を重視し遅延データを破棄すると、正確性が下がる
Beamにおけるストリーミングに対応するためのウィンドウ
- Fixed-time Window
- 固定長のウィンドウ
- レイテンシが存在しない理想の状況があるとしたら、固定長のウィンドウで始端から終端までカバーできる。
- 例: 1時間ごとのWebサイト訪問数集計
- Sliding-time Window
- 固定長のウィンドウをn分おきに開始する。
- 例: 10分毎に1時間幅のWebサイト訪問数の移動平均を計算
- Session Window
- 特定のキーに基づき集約
- 最小ギャップ時間を過ぎて到着したデータは別ウィンドウで処理
- 例: Webサイトへの訪問をユーザ単位にトラッキング
現実にはレイテンシがある。これにはWatermarkと集計のトリガを定義することで対応する。
- After Watermark
- After Processing Time
- After Count
総括
- データエンジニアリングの大きめな1要素としてETLがある。
- ETL, ELT, ELは要件によって使い分ける。
- ETLは並列処理や柔軟なスケールイン・アウトが求められることが多い。
- ゆえにクラウドとの相性良し
- GCPにおけるETLではDataproc, Dataflow, Data Fusionあたりが代表格。
Dataflowはオススメで、ざっくりだと以下のように使い分ける。- Hadoop関連を使いたかったらDataproc
- GUIを使いたかったらData Fusion
- それ以外はDataflow
- 特にストリーミング処理が求められるならDataflow超おすすめ。
- Cloud Pub/Subと組み合わせるなど