SageMaker Studio(チュートリアル Experiments編)
前提
notebookとジョブ
SageMaker Studioは要は「notebook」(実態はカスタマイズされたJupyter Lab)だが、これは基本的にEDA、Experimentsの一元管理、各ジョブ(学習、評価、チューニングなど)の起動、の用途に利用すべき。
各ジョブ自体はStudioの外で実行する。これは前述のnotebookで行うタスクと、各ジョブで行うタスクとでは必要なマシンリソースが異なるため。これらをすべてnotebook上で行ってしまうと並列化しづらいし、起動・停止の管理も面倒になる。
「ジョブ」は起動・停止を自動でやってくれるし必要に応じて並列化できるので、学習・評価・チューニングなどのバッチ的な処理はそちらに任せる。
他人のブログから拝借した画像だが、以下のイメージ。
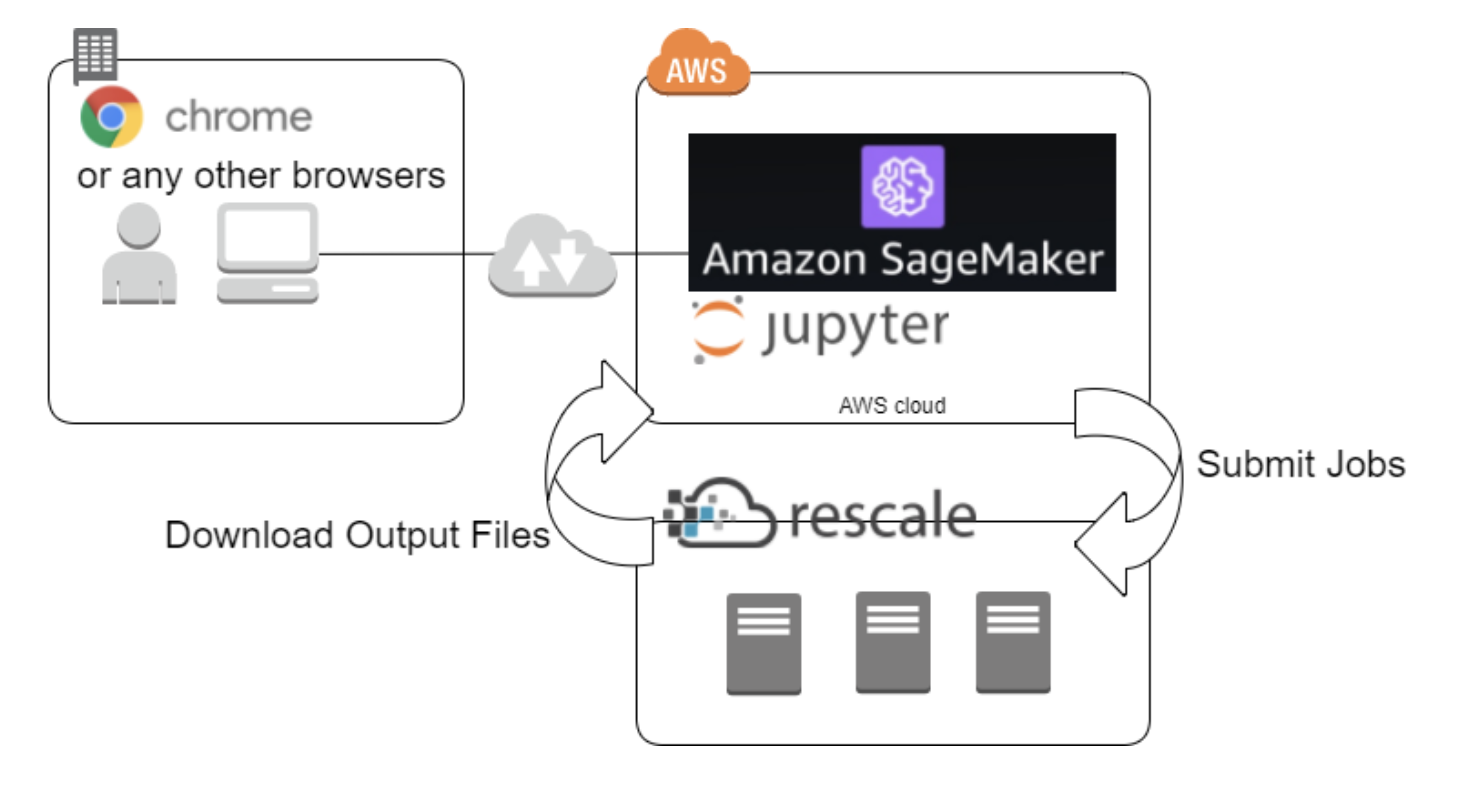
以降のチュートリアルもそのような内容になっている。
参考にする情報
公式チュートリアルを参考にしてやっていく。
手順はチュートリアル通りにやればできるので、細かいところは記載しない。
ここでは個人的な補足事項を記載していく。
チュートリアルの内容
チュートリアルは ここのjupyter notebookにまとめられている。
以降はこのnotebookから気になるところを抜粋する。
(チュートリアルでは、DebuggerやModel Monitorなど新機能が一通り揃っているが、本記事ではExperimentsまで)
ExperimentとTrial
SageMakerにExperimentsという機能が追加された。
いくつかの検証タスクを横串で比較するための機能で、細分化するとExperimentとTrialという概念がある。
公式ブログの説明としては以下の通り。
- Trial(トライアル) は、単一のトレーニングジョブを含む学習ステップの集合です。通常、トレーニングの手順には前処理、学習、モデル評価などが含まれます。また、Trial は入力(アルゴリズム、パラメーター、データセットなど)および出力(モデル、チェックポイント、メトリックなど)のメタデータにより強化されます。
- Experiment(実験)とは、単に Trial の集合であり、関連する学習ジョブのグループです。
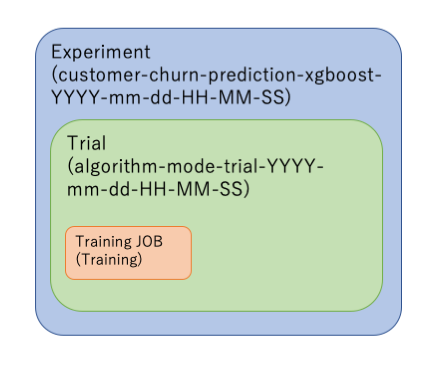
つまりExperimentとTrialの関係は以下のようなイメージ。
各ジョブ(図のオレンジ部分)は Trial Component という概念になる。
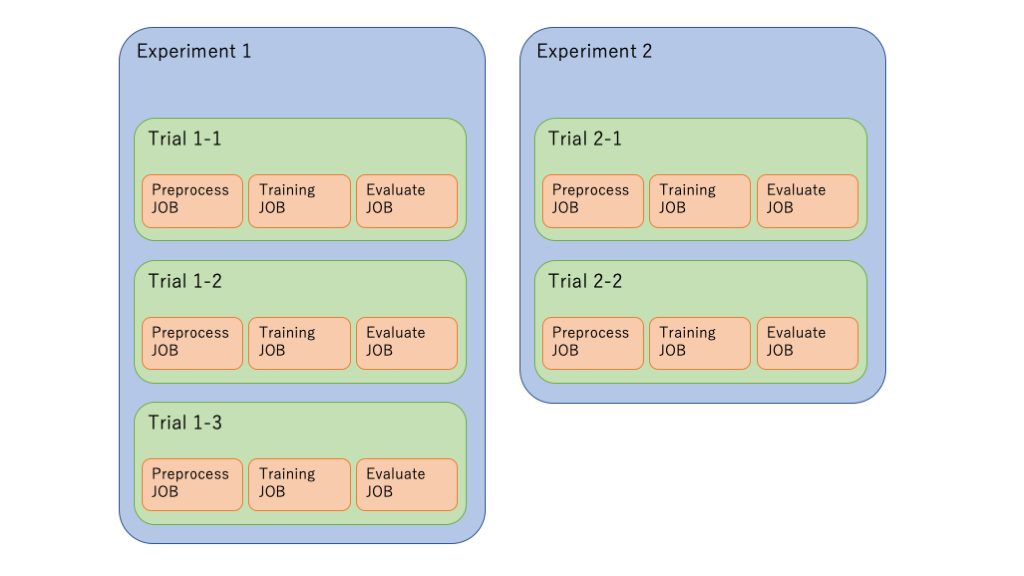
以下、実際のコードから使い方を抜粋。( 下記だけをコピペしても動かない。 実行時は 実際のnotebookを使うこと。)
pythonモジュールをimport。
from smexperiments.experiment import Experiment
from smexperiments.trial import Trial
Experimentを作成。
sess = sagemaker.session.Session()
create_date = strftime("%Y-%m-%d-%H-%M-%S", gmtime())
customer_churn_experiment = Experiment.create(experiment_name="customer-churn-prediction-xgboost-{}".format(create_date),
description="Using xgboost to predict customer churn",
sagemaker_boto_client=boto3.client('sagemaker'))
このセルを実行した時点で、Studio内のExperiments一覧に空のExperimentが追加される。
名前は experiment_name で指定した文字列になる。
ここではcustomer-churn-prediction-xgboost-YYYY-mm-dd-HH-MM-SSになっている。
Experiment名は使用しているSageMaker Studio内でユニークである必要がある。
次にTrialを作成。
同じくtrial_nameで指定した文字列でTrial名になる。
ここではalgorithm-mode-trial-YYYY-mm-dd-HH-MM-SSになっている。
Trial名も使用しているSageMaker Studio内でユニークである必要がある。
trial = Trial.create(trial_name="algorithm-mode-trial-{}".format(strftime("%Y-%m-%d-%H-%M-%S", gmtime())),
# ここのexperiment_nameでExperimentに紐付けていると思われる
experiment_name=customer_churn_experiment.experiment_name,
sagemaker_boto_client=boto3.client('sagemaker'))
学習ジョブを作成。
ジョブは Trial Component にあたる。
Trial Component名はTrialComponentDisplayName で指定することになるが、ここではTrainingという名前になっている。
これはユニークである必要はないみたい。(複数の同名Trial Componentを、1つのTrialに紐づけてもOK。例えばTrainingを複数回実行することもできる。必要があるかは別として)
xgb = sagemaker.estimator.Estimator(image_name=docker_image_name,
role=role,
hyperparameters=hyperparams,
train_instance_count=1,
train_instance_type='ml.m4.xlarge',
output_path='s3://{}/{}/output'.format(bucket, prefix),
base_job_name="demo-xgboost-customer-churn",
sagemaker_session=sess)
xgb.fit({'train': s3_input_train,
'validation': s3_input_validation},
experiment_config={
# ここでもExperimentと紐付け。2回指定しないといけないのめんどいな...
"ExperimentName": customer_churn_experiment.experiment_name,
# Trialとも紐付ける
"TrialName": trial.trial_name,
# Trial内で表示されるジョブ(Trial Component)の名前
"TrialComponentDisplayName": "Training",
}
)
EstimatorとはSageMakerの提供する学習ジョブ生成用のクラス。
ここではdocker_image_nameとある通り、あらかじめSageMakerが提供しているXGBoostの学習実行が可能なDockerイメージを指定している。
独自の学習実行をしたいときは、ここを自前のDockerイメージに変更することになると思われる。
ここでのdocker_image_nameは以下のようにして事前に取得している。
from sagemaker.amazon.amazon_estimator import get_image_uri
docker_image_name = get_image_uri(boto3.Session().region_name, 'xgboost', repo_version='0.90-2')
docker_image_nameには257758044811.dkr.ecr.us-east-2.amazonaws.com/sagemaker-xgboost:0.90-2-cpu-py3という文字列が入っていた。
上記のようにfit関数を呼び出すことで、SageMakerの学習ジョブが発行される。fit呼び出し後、AWSコンソールのSageMakerダッシュボードからも学習ジョブが発行されていることを確認できる。(InProgressとなっているジョブ)
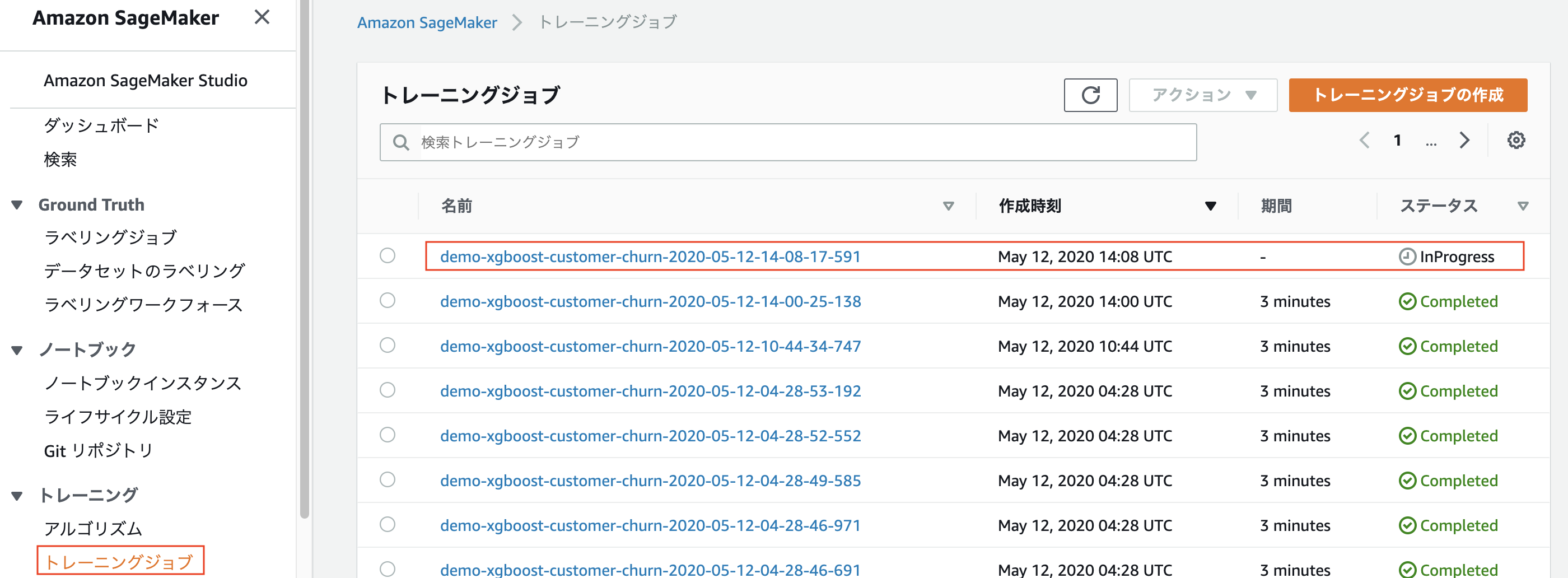
上記のようにコードを書いて実行すると、1つのTrialに対して複数のTrial Component(つまり学習ジョブ、評価ジョブなど)を紐付けて管理していくことになる。 さっきの図でいうと以下のような感じになっている。
パラメータを変えて複数の学習ジョブを実行
ここまではExperiment:Trial:TrialComponent = 1:1:1の実行だった。
次はパラメータを変更して精度の良いものを探索するような作業を想定したチュートリアル。
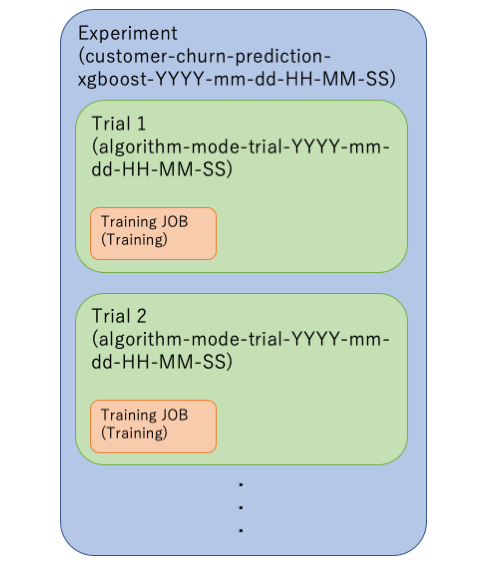
ここでは1つのExperimentに複数のTrialを紐付けて実行する。
前述の通り、1つのTrial内で学習ジョブを複数回紐付けることもできるが、そうはせずにTrialを分けた方が理解しやすいだろう。
以下の感じ。
実際のコードは以下。
min_child_weights = [1, 2, 4, 8, 10]
for weight in min_child_weights:
hyperparams["min_child_weight"] = weight
trial = Trial.create(trial_name="algorithm-mode-trial-{}-weight-{}".format(strftime("%Y-%m-%d-%H-%M-%S", gmtime()), weight),
experiment_name=customer_churn_experiment.experiment_name,
sagemaker_boto_client=boto3.client('sagemaker'))
t_xgb = sagemaker.estimator.Estimator(image_name=docker_image_name,
role=role,
hyperparameters=hyperparams, # ここがforループごとに変わる
train_instance_count=1,
train_instance_type='ml.m4.xlarge',
output_path='s3://{}/{}/output'.format(bucket, prefix),
base_job_name="demo-xgboost-customer-churn",
sagemaker_session=sess)
t_xgb.fit({'train': s3_input_train,
'validation': s3_input_validation},
wait=False, # これで非同期に複数のジョブが発行される
experiment_config={
"ExperimentName": customer_churn_experiment.experiment_name,
"TrialName": trial.trial_name,
"TrialComponentDisplayName": "Training",
}
)
やっていることはほぼ変わらず。
ポイントとしてはfitを呼び出すときにwait=Falseとしており、これで学習ジョブが終わることを待たずに非同期に複数の学習ジョブを発行できる。
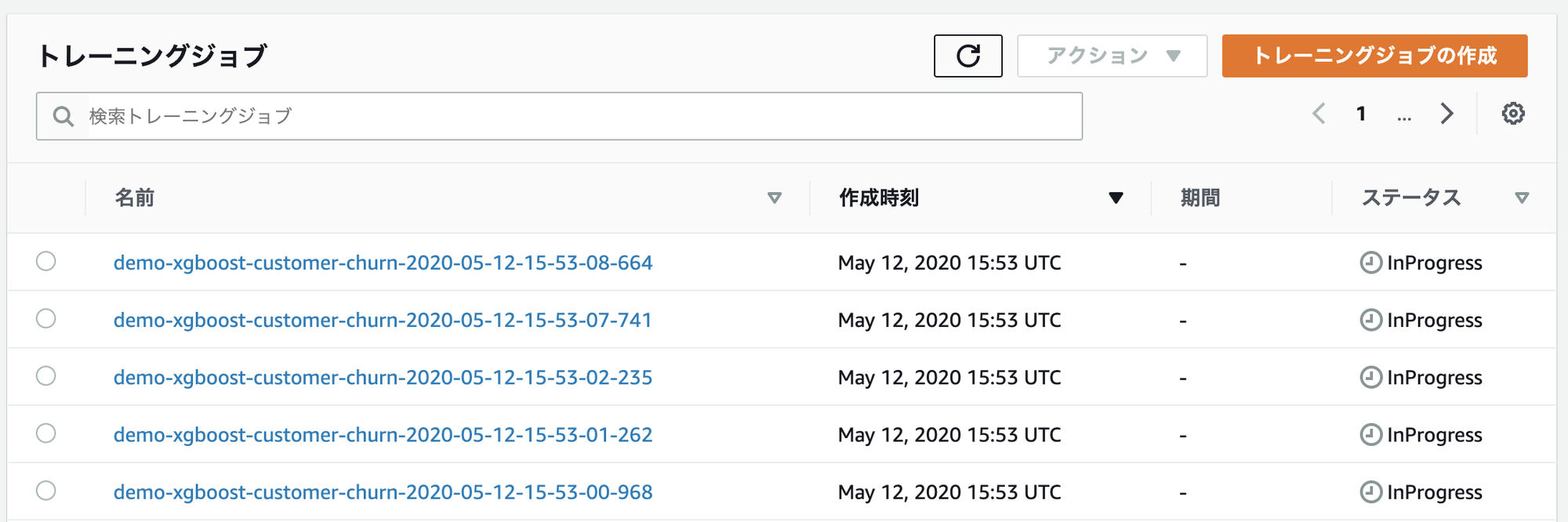
上図からInProgressのジョブが5つ同時に発行されていることがわかる。
複数のTrialの結果を比較
ここがSageMaker StudioとExperimentsの最大の売りだと思うのだが、チュートリアルで書いてある以外に特筆すべき点がないので詳しくは割愛。
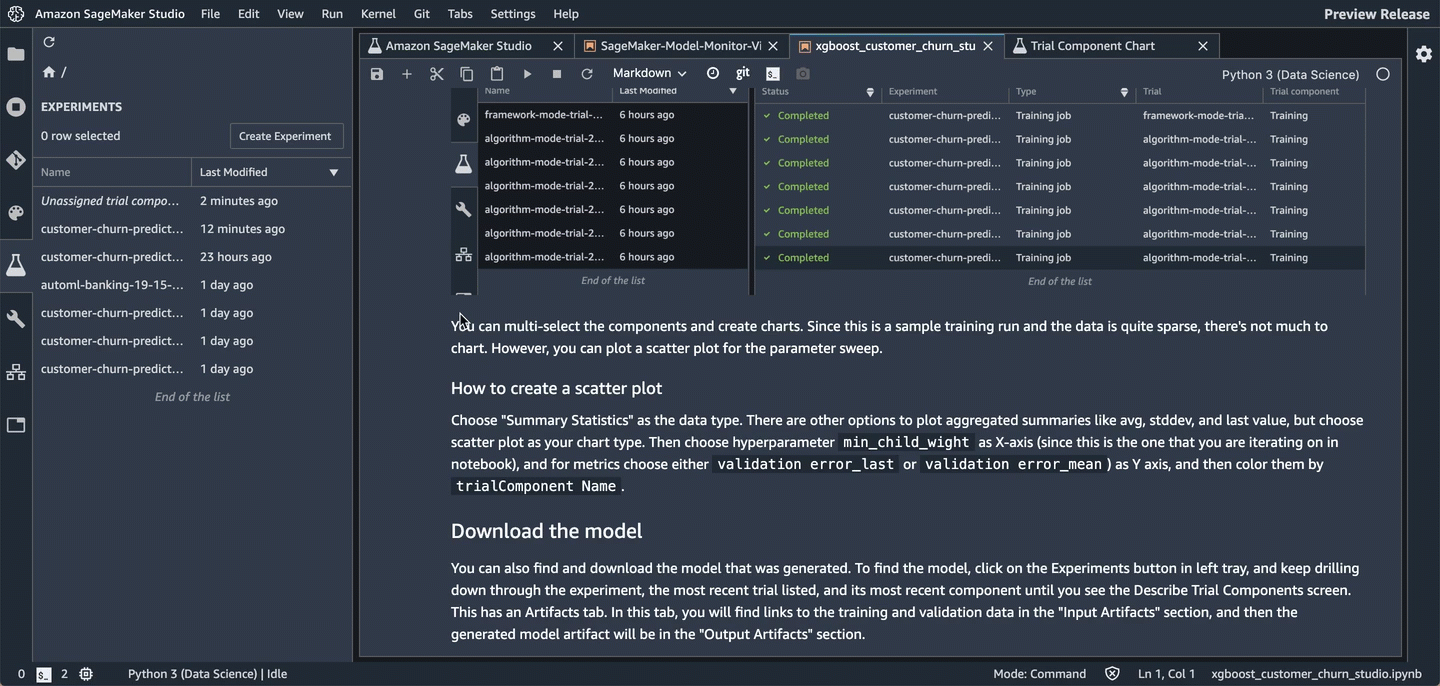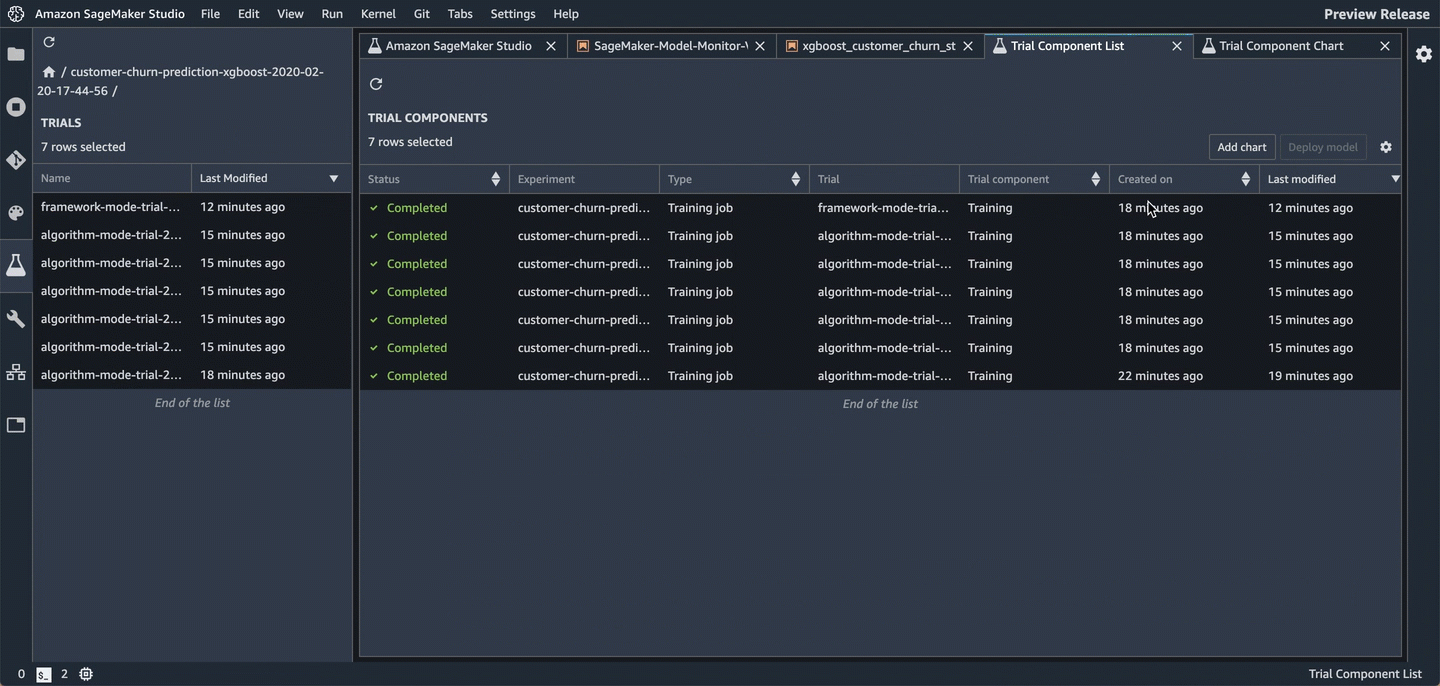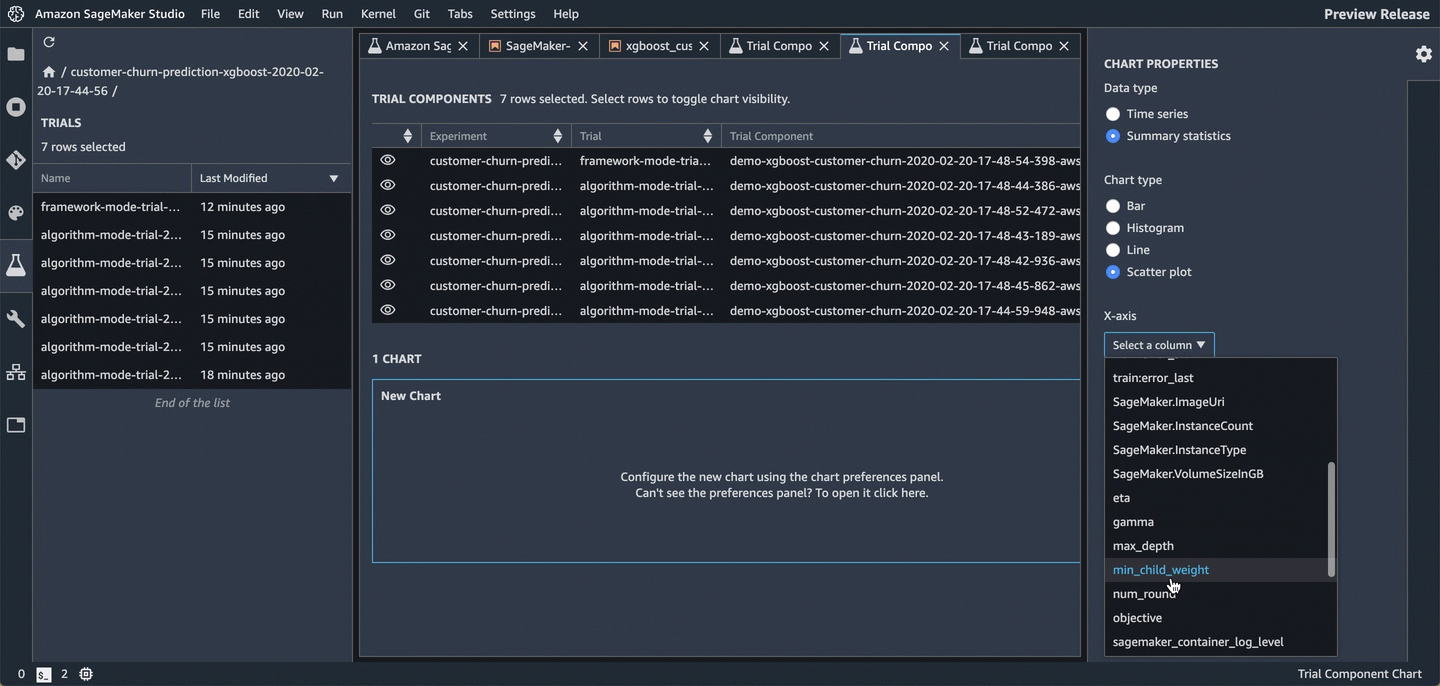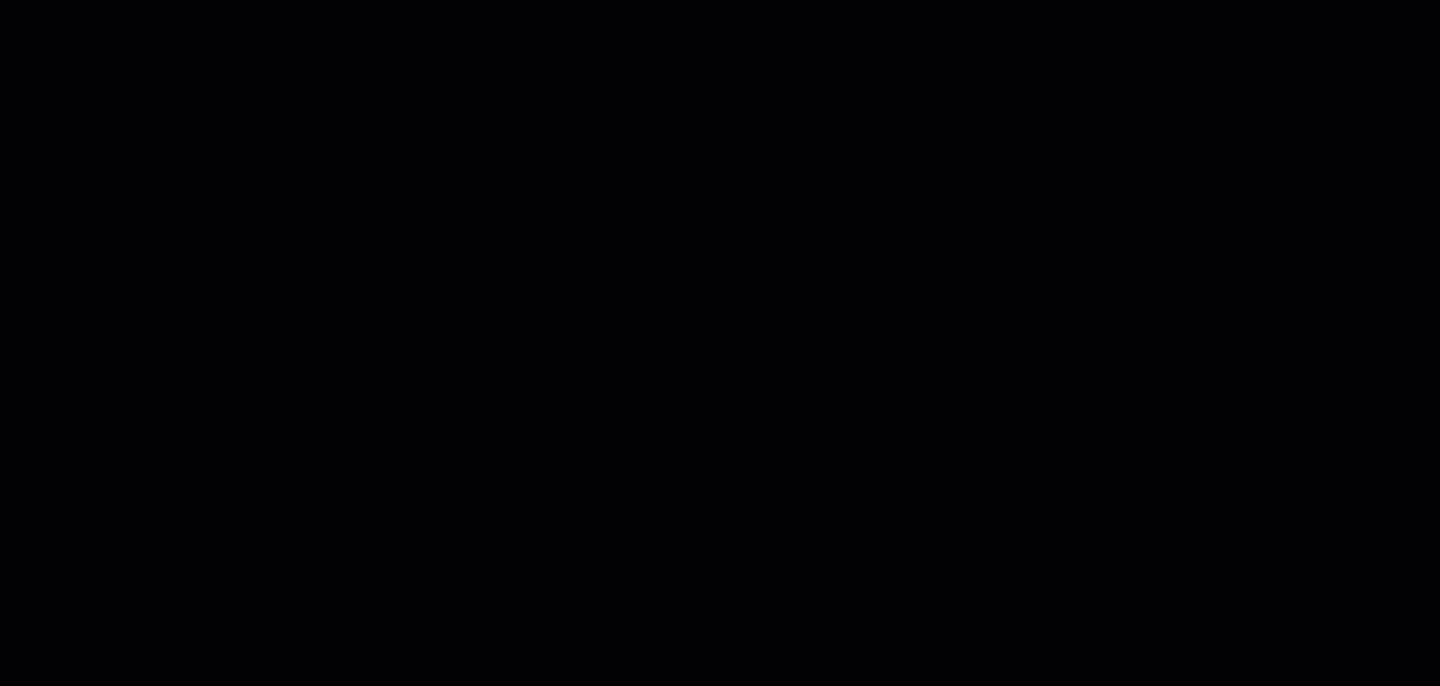
ざっくり以下の手順。
- 複数のTrialをShift+右クリックで複数選択して
Open in trial component list Trial Component Listというタブ内で、同じく複数のTrialを選択してADD CHARTTrial Component Chartというタブ内で、同じく複数のTrialを選択してADD CHART- 右に出てくる
CHART PROPERTIESで可視化の内容を選択
下図は チュートリアル内のgifを引用。
Jupyter Lab上で可視化できるのは便利かもしれないが、操作に慣れないとやや使いづらい印象はある…
なんだろう、手順の多さが煩雑に感じるのだろうか。